

GLM-4V-9B PyTorch模型微调最佳实践
引言
GLM-4V-9B是智谱AI推出的最新一代预训练模型GLM-4系列中的开源多模态版本。GLM-4V-9B具备1120 * 1120高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B表现出超越GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max和Claude 3 Opus的卓越性能。
环境准备
安装Ascend CANN Toolkit和Kernels
安装方法请参考安装教程或使用以下命令。
# 请替换URL为CANN版本和设备型号对应的URL
# 安装CANN Toolkit
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run
bash Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run --install
# 安装CANN Kernels
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run
bash Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run --install
# 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
安装openMind Hub Client以及openMind Library
- 安装openMind Hub Client
pip install openmind_hub
- 安装openMind Library,并安装PyTorch框架及其依赖。
pip install openmind[pt]
更详细的安装信息请参考魔乐社区官方的环境安装章节。
下载GLM-4代码
git clone https:/github.com/THUDM/GLM-4.git
模型链接和下载
GLM-4V-9B模型由社区开发者在魔乐社区贡献:
GLM-4V-9B: https://modelers.cn/models/AI-Research/glm-4v-9b
通过Git从魔乐社区下载模型的repo:
# 首先保证已安装git-lfs(https://git-lfs.com)
git lfs install
git clone https://modelers.cn/AI-Research/glm-4v-9b.git
# 环境依赖 python==3.10
pip install -r glm-4v-9b/examples/requirements.txt
模型推理
用户可以使用openMind Library进行模型推理,具体如下:
示例图片:

新建glm-4v-9b-chat.py推理脚本:
import torch
import argparse
from PIL import Image
from openmind import AutoModelForCausalLM, AutoTokenizer
from openmind import is_torch_npu_available
from openmind_hub import snapshot_download
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to model",
default=None,
)
args = parser.parse_args()
return args
def main():
args = parse_args()
if args.model_name_or_path:
model_path = args.model_name_or_path
else:
model_path = snapshot_download("AI-Research/glm-4v-9b", revision="main", resume_download=True,
ignore_patterns=["*.h5", "*.ot", "*.mspack"])
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
query = '图片中的男人在吃什么?'
if is_torch_npu_available():
device = "npu:0"
else:
device = "cpu"
image = Image.open("example.png").convert('RGB')
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
if __name__ == "__main__":
main()
执行推理脚本,若模型已下载,可通过--model_name_or_path传入模型本地路径。
python glm-4v-9b-chat.py
推理结果如下:

模型微调
准备数据集
多模态模型微调使用自定义数据集,数据集格式如下:
{
"messages": [
{
"role": "user",
"content": "图片中的动物是什么?",
"image": "xxx/xxx.jpg"
},
{
"role": "assistant",
"content": "图片中有一只猫。"
},
{
"role": "user",
"content": "图片中的猫在做什么?"
},
{
"role": "assistant",
"content": "这只猫坐在或站在桌子上,桌子上有很多食物。"
}
]
}
微调
修改GLM-4/finetune_demo/finetune_vision.py
from typing import Annotated, Any, Union
为
from typing import Any, Union
from typing_extensions import Annotated
使用以下命令进行微调:
cd GLM-4/finetune_demo
python finetune_vision.py data/xxx ./glm-4v-9b configs/lora.yaml
注意:data/xxx为数据集路径,该路径下需要包含train.jsonl、dev.jsonl和test.jsonl数据集。train.josnl是必须存在的训练数据集,如果路径中没有dev.jsonl和test.jsonl数据集,需要在configs/lora.yaml文件中删除这两个数据集。./glm-4v-9b为预训练模型路径。
微调可视化
训练Loss可视化:
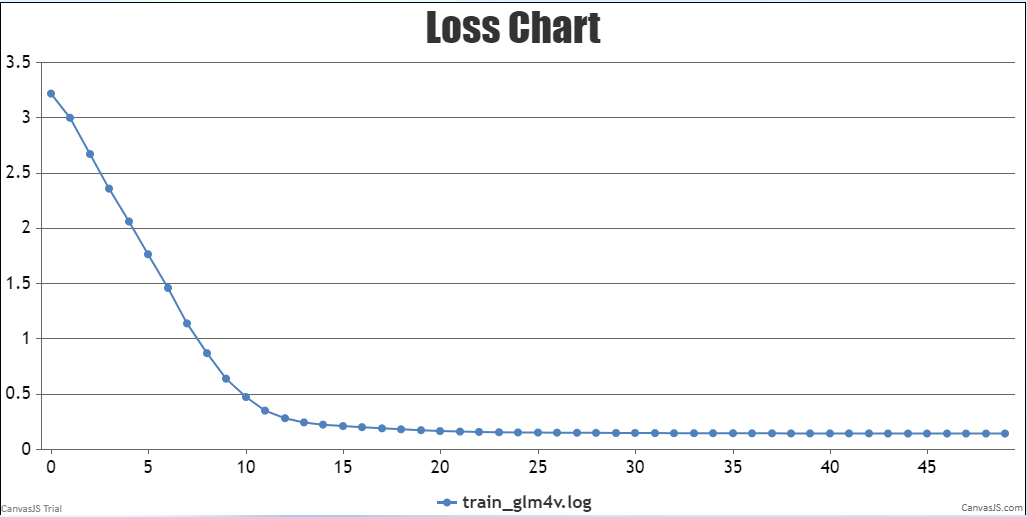
微调后推理
修改GLM-4/finetune_demo/inference.py:
messages = {
{
"role" : "user", "content": "#裙子#夏天"
}
}
修改为:
messages = [
{
"role": "user",
"content": "图片中的男人在吃什么?", # 需要推理的prompt
"image": Image.open("your image").convert("RGB") # your image为需要推理的图片
}
]
执行命令:
python inference.py your_finetune_path # your_finetune_path为微调后权重的保存路径,默认在xxx/GLM-4/finetune_demo/output/checkpoint-**
推理结果:
