

模型可用性测试
关于模型可用性测试
模型可用性测试定义
模型可用性测试旨在验证用户基于本文档编写的自定义推理用例在NPU上执行是否通过。
如何进行模型可用性测试
遵循下文模型可用性测试运行脚本的指导编写脚本。注意:只有模型拥有者或模型所在组织下有写权限的成员可以提交模型可用性测试申请。
选择目标模型,进入模型介绍页面。
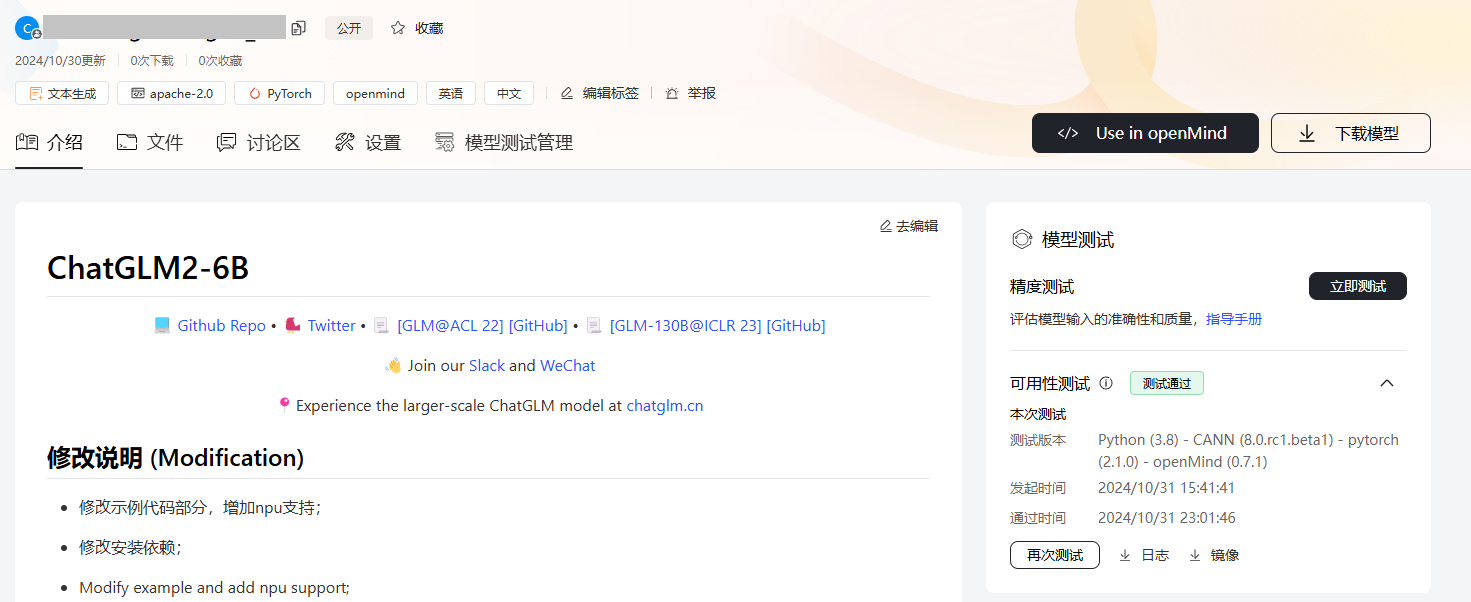
在右侧的“可用性测试”区域,若该模型为首次测试则单击“立即测试”,若已进行过测试则单击“再次测试”进入模型可用性测试界面。

在弹出的“可用性测试”框中,选择各个部件的输入信息并单击“确认”。

等待模型可用性测试用例执行完成。
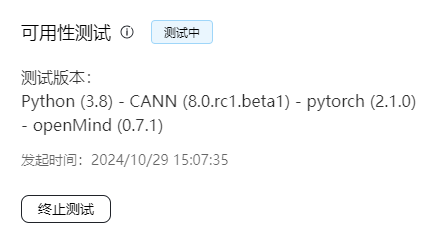
(可选) 当模型处于“测试中”时,用户可以单击“终止测试”手动停止测试。更多的模型终止的场景,请参考终止场景说明。
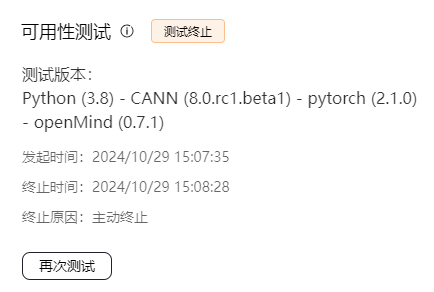
当用例执行完成后,在“可用性测试”区域显示执行结果。当测试通过时,提供日志下载和镜像下载链接,当测试失败时,只提供日志下载。
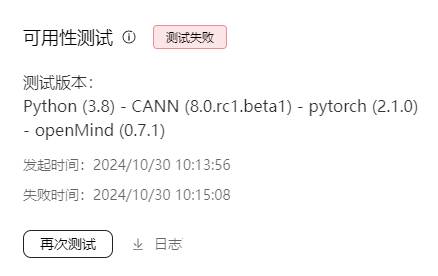
模型可用性测试交互状态
| 模型拥有者(写权限用户)视角 | 非拥有者视角 | |
|---|---|---|
| 未测试 | | 无 |
| 测试中 | | 无 |
| 测试终止 | | 无 |
| 测试通过 | | 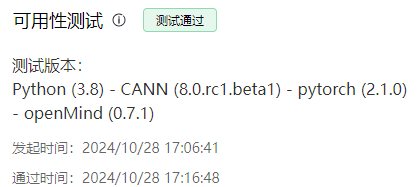 |
| 测试失败 | | 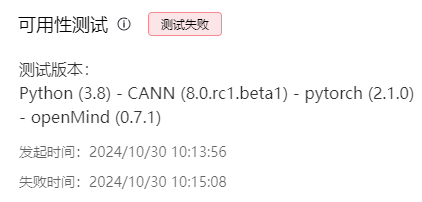 |
模型可用性测试终止场景
模型可用性测试的终止场景分为用户主动终止、以及因为模型库相关操作导致的间接终止。在测试终止的状态页面,会显示具体的终止原因。
主动终止
用户通过测试界面的终止按钮发起终止请求
间接终止
- 模型仓文件发生变更(commitID变化)
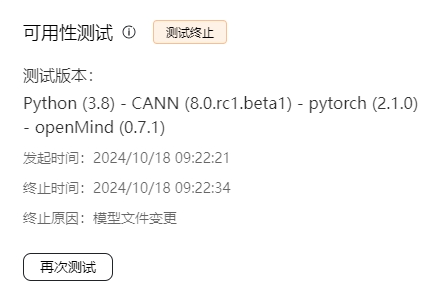
- 模型仓由公开仓转为私有仓
该场景下,模型测试界面会隐藏,终止原因会推送到模型拥有者(写权限用户)的消息中心。
- 模型被下架
该场景下,模型测试界面会隐藏,终止原因会推送到模型拥有者(写权限用户)的消息中心。
模型可用性测试运行脚本
模型可用性测试脚本以inference.py为入口。脚本编写请严格遵照本文档的规范。
模型可用性测试脚本必须包含以下两个文件:
- requirements.txt:该脚本运行需配置的相应module (如果没有需要安装的依赖,请创建一个空的requirements.txt文件)。
- inference.py: 基于openMind Library的可运行的推理脚本。
文件位置
requirements.txt和inference.py必须位于examples文件夹下。
- examples文件夹路径:位于根目录下
- requirements.txt路径:examples/requirements.txt
- inference.py路径: examples/inference.py
requirements.txt文件(可选)
请设置NPU下运行该脚本需要配置的对应依赖,默认openMind Library已安装,torch_npu与mindspore根据选择的框架版本由环境提供,因此在requirements.txt中不需要重复上述依赖的添加(可能会导致依赖安装冲突异常)。库的依赖脚本格式示例如下:
transformers==4.37.0
accelerate==0.27.2
如果不需要添加任何依赖,该.txt文件可不提供,测试任务会跳过依赖安装。
inference.py文件
该文件是一个基于openMind Library的可加载权重进行推理的脚本,该推理脚本运行方式无严格限制,以下为脚本规范。
加载openMind Library
import argparse
import torch
from openmind import pipeline, is_torch_npu_available
构造执行脚本所需要的入参
模型权重由自动化测试执行侧根据测试发起时仓库的commit id在执行测试前提前下载。请保留model_name_or_path入参用于执行侧传入权重的本地路径。
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to model",
default=None,
)
args = parser.parse_args()
return args
设定脚本可在NPU上运行
此处npu:0设置非强要求,如果模型推理前向支持device_map='auto',可直接使用device_map。
if is_torch_npu_available():
device = "npu:0"
else:
device = "cpu"
权重下载
用户通过model_name_or_path入参提供本地权重路径,模型推理从执行机本地加载权重。
model_path = args.model_name_or_path
前向推理
- 支持pipeline
# 如果模型推理支持`device_map`,可直接忽略`device`设置, 并增加device_map="auto"
generator = pipeline('text-generation', model=model_path, device=device)
output = generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
- 不支持pipeline,需要从openmind import对应的类手动加载进行前向。例如 from openmind import AutoModelForCausalLM, AutoTokenizer
from openmind import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
# 如果模型推理支持`device_map`,可直接忽略`device`设置, 并增加device_map="auto"
model = AutoModelForCausalLM.from_pretrained(model_path, device=device, torch_dtype=torch.bfloat16, trust_remote_code=True)
model = model.eval()
inputs = tokenizer("[|Human|]:三国演义的作者是谁?[|AI|]:", return_tensors="pt").to(model.device)
pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
- 不支持以上两种方法,需要从transformers导入对应的类。以BitImageProcessor和BitForImageClassification类为例
from datasets import load_dataset
from transformers import BitImageProcessor, BitForImageClassification
dataset = load_dataset("./cats_image")
image = dataset["train"]["image"][0]
feature_extractor = BitImageProcessor.from_pretrained(model_path)
model = BitForImageClassification.from_pretrained(model_path).to(device)
inputs = feature_extractor(image, return_tensors="pt").to(device)
with torch.no_grad():
logits = model(**inputs).logits
predicted_label = logits.argmax(-1).item()
print(f'>>>result={model.config.id2label[predicted_label]}')
- Diffusers类的推理脚本。openMind Library暂时不支持Diffusers类pipeline,可以直接从diffusers导入pipeline进行推理
from diffusers import DiffusionPipeline
from PIL import Image
pipe = DiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to(device)
prompt = "An astronaut riding a green horse."
images = pipe(prompt=prompt).images[0]
全流程代码示例
inference.py
import argparse
import torch
from openmind import pipeline, is_torch_npu_available
from openmind_hub import snapshot_download
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to model",
default=None,
)
args = parser.parse_args()
return args
def main():
args = parse_args()
model_path = args.model_name_or_path
if is_torch_npu_available():
device = "npu:0"
else:
device = "cpu"
generator = pipeline('text-generation', model=model_path, device=device)
output = generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
print(f">>>output={output}", flush=True)
if __name__ == "__main__":
main()