
本页内容 
快速上手
入门导读
- 如果您是新手,想要快速体验魔乐社区全流程操作,请参考本节快速上手指导文档。
- 如果本地开发环境已准备好,想要获取更多模型进一步探索使用,请参考模型库指导文档进行学习和操作。
- 如果想开展特定的Task任务,并想了解Task使用的模型、训练、推理及导出的模型信息,请参考Task指导文档了解详情。
- 如果您想成为社区的贡献者,请参考贡献者指南,学习成为魔乐社区贡献者的基础操作和平台相关规范,助力社区知识共享。
获取模型
您可以访问魔乐社区模型库,获取平台上所有公开的模型,并根据模型标签或任务筛选所需的模型。
接下来以PyTorch-NPU/qwen1.5_7b_chat模型为例,带您深度体验魔乐社区模型库。
进入魔乐社区模型库后,您可以通过筛选“文本分类”任务或者在搜索框输入模型名称的关键词,定位到所需的模型上。模型卡片中将展示模型的基础信息、任务类型、模型使用的AI框架等信息,帮助您快速了解模型关键信息,判断其是否为目标模型。
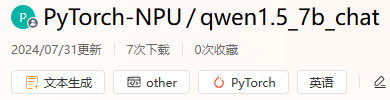
单击模型卡片,进入模型详情页内,查看模型介绍。在这里,您可以了解模型所有者提供的详细信息和操作指导。
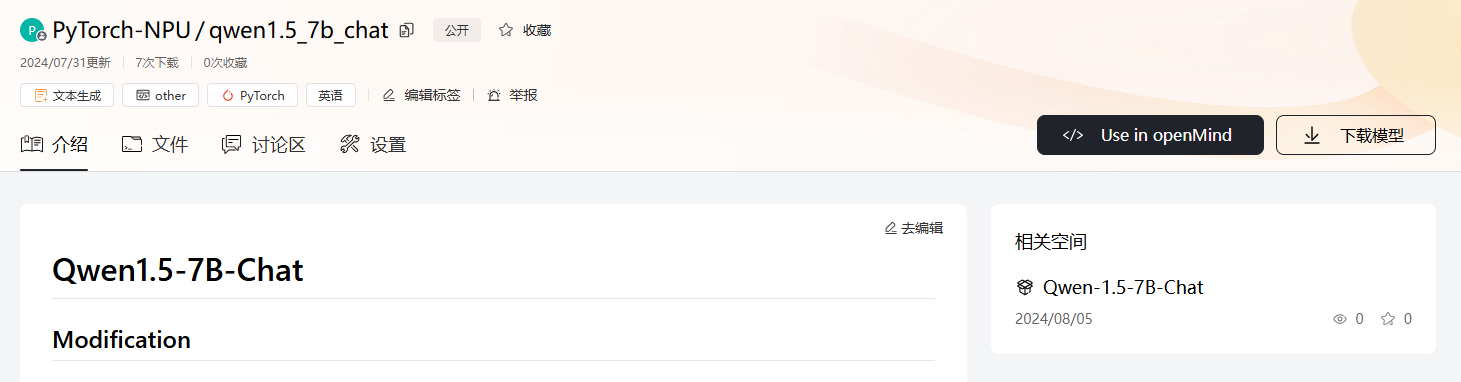
根据右侧关联的体验空间,可以跳转至体验空间,在线体验模型在具体应用程序中的效果。
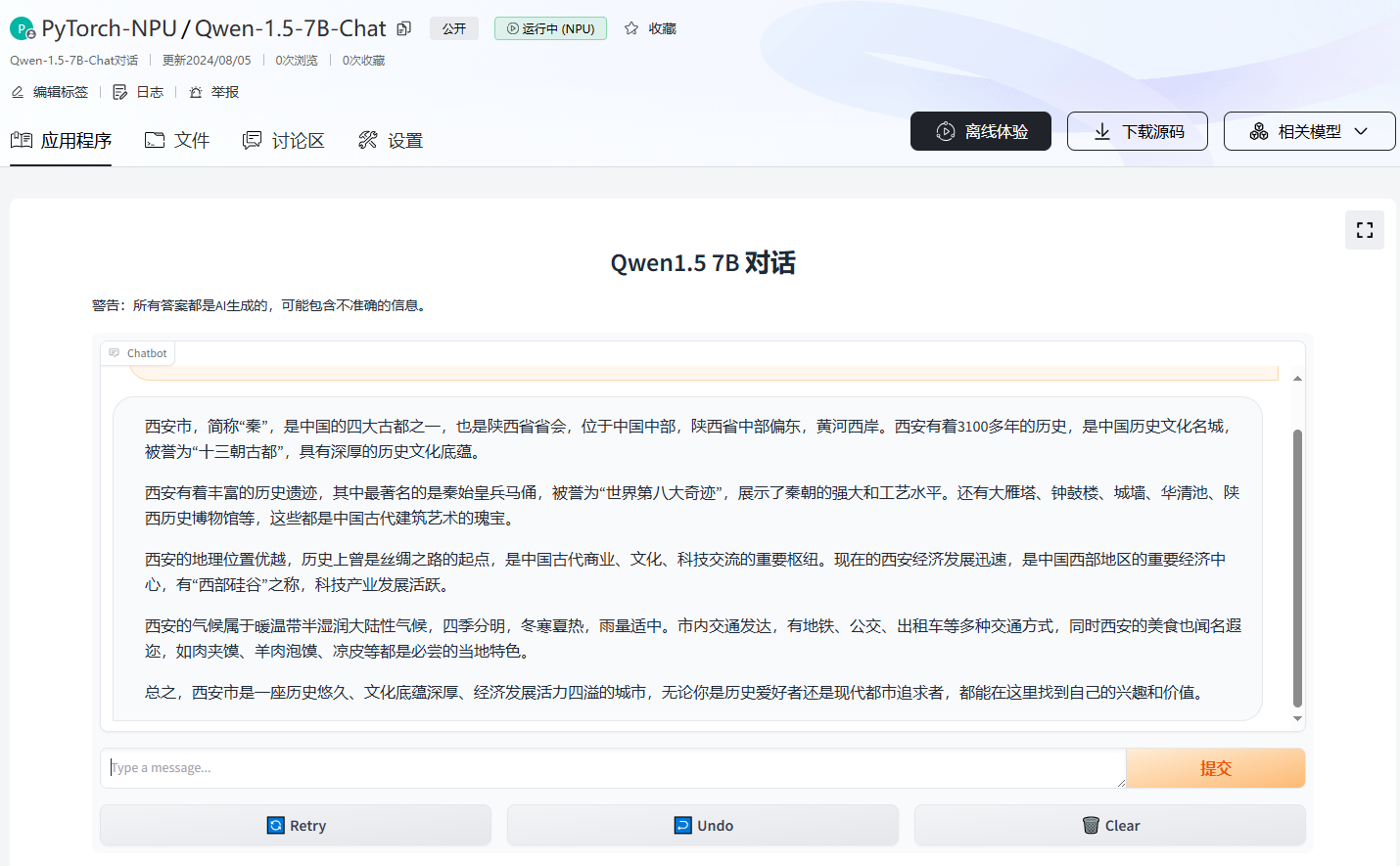
除了在线体验关联的体验空间之外,用户可以下载模型文件,当前支持Git和openMind Hub Client等方式下载,具体操作请参考下载模型。
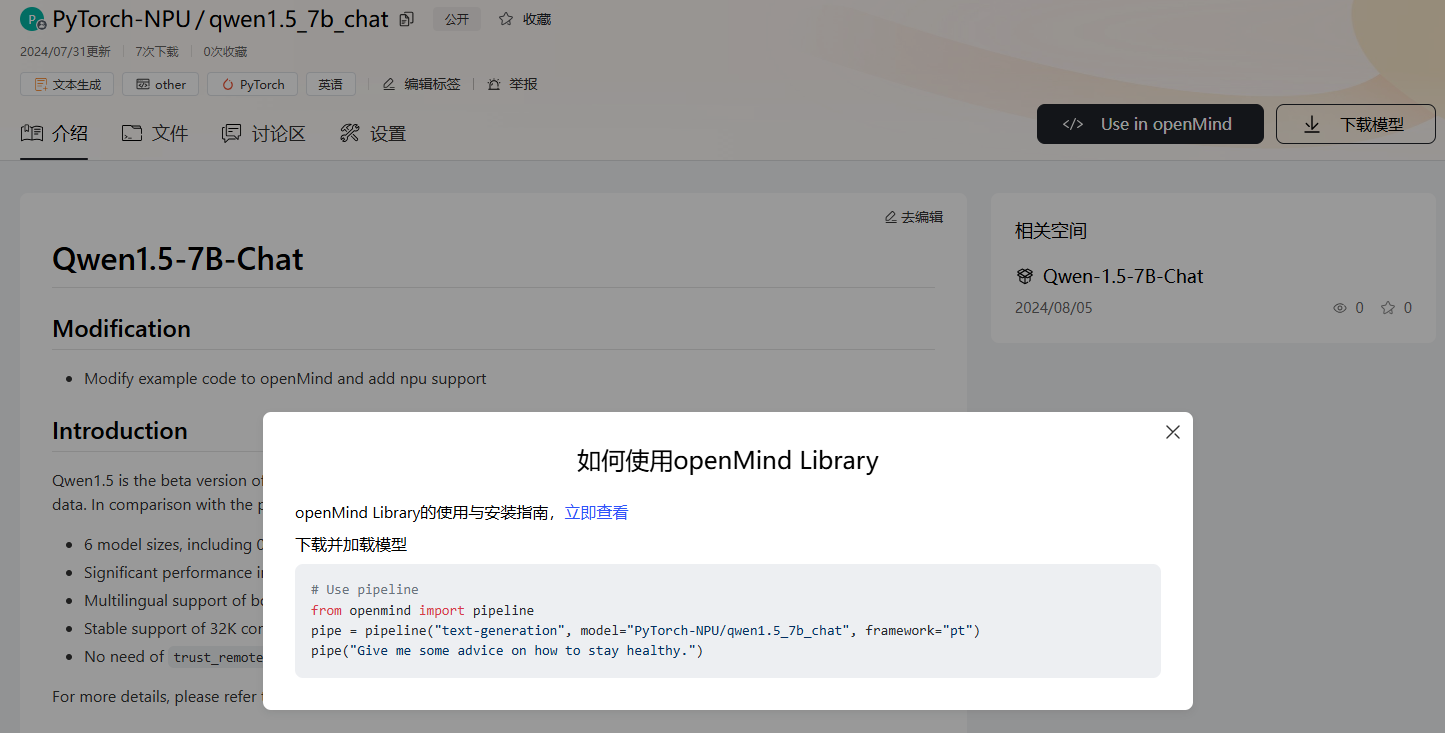
如果您想进一步验证模型效果,请单击模型右上角的“Use in openMind”,在已准备好本地环境(参考“环境准备”)的前提下,下载并加载模型,Web界面命令示例如下:
环境准备
本地运行模型时,本地开发环境需要满足如下要求:
- 安装Python环境:支持Python 3.8/3.9/3.10版本,可参考安装说明。
- 安装深度学习框架:支持MindSpore 2.3.1、PyTorch 2.1.0两大深度学习框架进行模型训练和推理,当前快速上手样例请安装PyTorch 2.1.0。
- 安装openMind Hub Client:使用pip安装openMind Hub Client。
- 安装openMind Library:使用pip安装openMind Library。
更详细的安装信息请参考环境安装。
实践:文本的情感分析任务
使用openMind Library等工具套件仅需简单的几行代码即可完成模型推理,本节以文本的情感分析任务为例,请参考如下步骤进行模型推理。
操作步骤
- 使用“用户名/仓库名”的格式指定魔乐社区模型库内的情感分析微调的多语言BERT模型distilbert_base_uncased_finetuned_sst_2_english模型代码仓,并使用
AutoModelForSequenceClassification和AutoTokenizer加载该代码仓中的预训练模型和关联的分词器。 - 通过
pipeline()指定模型和分词器。 - 通过
classifier对输入的文本内容进行情感分析。 - 查看分析结果。
完整的示例代码如下:
python
from openmind import pipeline
from openmind import AutoTokenizer, AutoModelForSequenceClassification
# 指定模型库内的PyTorch-NPU/distilbert_base_uncased_finetuned_sst_2_english代码仓
model_name = "PyTorch-NPU/distilbert_base_uncased_finetuned_sst_2_english"
# 从模型库下载并加载该模型及分词器
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 创建分词器
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# 输入文本,进行情感分析
classifier("Welcome to openMind!")
查看输出结果:
python
[{'label': 'POSITIVE', 'score': 0.999784529209137}]
后续操作
至此,我们已经在魔乐社区完成了一个基础的深度学习任务,魔乐社区不仅提供了丰富的模型资源,还支持用户在魔乐社区上在线体验模型的训练和推理,丰富的API接口支持开发功能强大的推理应用程序,探索更多开发工具和生态资源,可参考如下教程和样例开启深度体验之旅。