DeepSeek-R1-Distill系列模型魔乐社区微调实践
LLM原有的Pretrain预训练 -> SFT监督微调 -> RLHF强化学习已成为经典的训练路线,那是否可以有新的路径更快更好地达成目标,同时提升复杂任务下的推理能力。DeepSeek-R1系列模型为开源社区探索出了一系列创新的方法。
- R1-Zero 基于 DeepSeek-V3-Base,直接通过纯RL(强化学习) 训练,无 SFT (监督微调);R1 则基于 R1-Zero,先利用少量人工标注的高质量数据进行冷启动微调,然后再进行 RL。该方法减少了学习阶段,也降低了对高质量指令数据的依赖。研究人员发现,在该训练过程中,R1-Zero有顿悟现象,会自发学习到有效的推理能力,同时过小的模型顿悟效果不显著。
- 对于小型模型,DeepSeek发现相比原训练路线,通过将有优秀能力的老师输出的高质量合成数据蒸馏给学生模型,可以更有效和快速地提升对应的模型能力。这里使用了目前社区的Qwen和LLaMA系列模型作为蒸馏对象,实验也证明了该方法的价值,相关模型也被开源在了DeepSeek-R1-Distill系列。
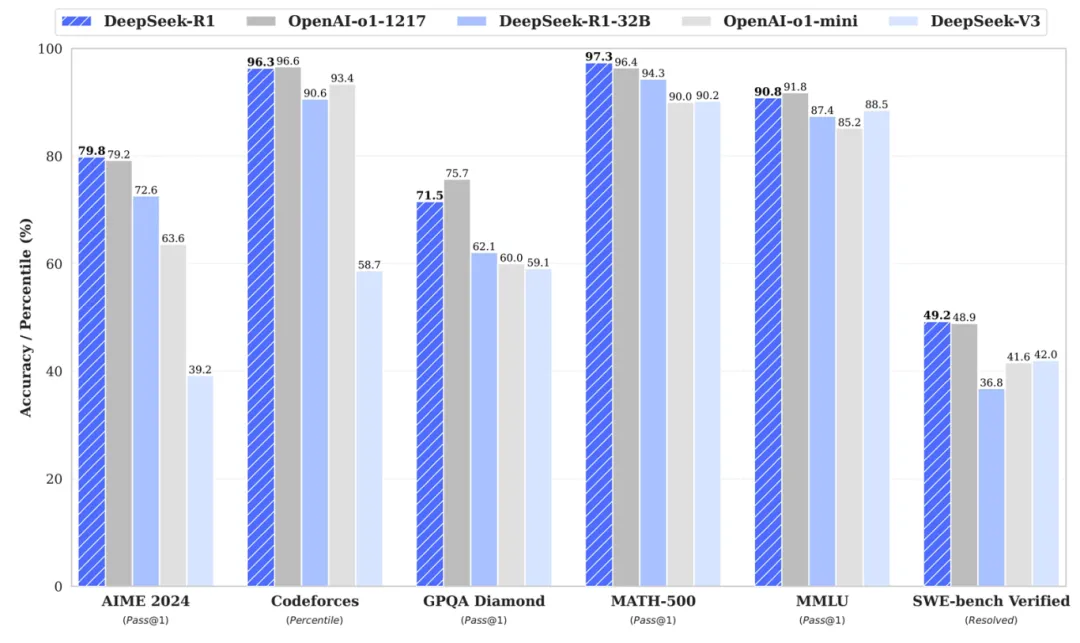
上图为DeepSeek-R1系列的部分评测数据,DeepSeek-R1-Distill系列模型相比原版模型也会有更优秀的通用能力和复杂任务处理能力,对于下游任务垂域微调是一个合适的基座选择。本文以该系列模型和Mind应用使能套件为例介绍在Atlas 900 A2 PoD上的微调方法。本教程将包含如下内容:
环境准备
下载模型
自定义数据集配置方法
deepseek_r1模型训练配置
训练启动方式
1 环境准备
基础环境配置请参考环境准备文档
需要注意的是,由于deepseek_r1 的支持还属于预览版阶段,需要源码安装,操作步骤是将其中的步骤5 pip安装openMind Library阶段更改为如下方式,其他不变
git clone https://gitee.com/ascend/openmind.git
cd openmind
pip install .[pt]
2 模型下载
可通过带lfs的git从魔乐社区进行模型下载,如
git clone https://modelers.cn/AI-Research/DeepSeek-R1-Distill-Qwen-7B.git
由于模型路径后续会使用到,这里假设下载后模型的位置在/model/DeepSeek-R1-Distill-Qwen-7B
3 自定义数据集准备
微调支持alpaca和sharegpt两种主流格式,使用json文件存储,alpaca格式下的O1思维链的多轮样例如下:
{
"instruction": "如下方程是否可以因式分解:",
"input": "x²-5x+6 = (x-2)(x-3)",
"output": "<think>1. 问题分析:方程的结构是否可以因式分解?2. 尝试分解:x²-5x+6 = (x-2)(x-3) 3. 验证解:x=2和x=3代入原方程成立。</think><answer>解为x=2或x=3</answer>",
"history": [
["你是谁", "我是您的助理,请问有什么可以帮您?"]
]
}
其中think部分为推理中间过程,answer部分为答案结果。训练数据按照格式准备好后,需要编写一个 custom_dataset_info.json文件,用于说明数据具体的情况,比如如下配置说明了数据集的位置是/data/custom_data.json, 并将数据的字段名称与标准的名称进行了映射, 并将数据集命名为custom_data_name。
{
"custom_data_name": {
"file_name": "custom_data.json",
"local_path": "/data/",
"split": "train",
"columns": {
"prompt" : "instruction",
"query": "input",
"response" : "output",
"history" : "history"
}
}
}
4 训练配置与启动
Mind应用使能套件提供了低代码配置化的方式启动训练流程,只需要编写一个train_sample.yaml配置文件,定义训练过程中需要的不同参数即可。这里以全参微调为例子进行说明。
model_name_or_path: /model/DeepSeek-R1-Distill-Qwen-7B
trust_remote_code: True
# method
stage: sft
do_train: true
finetuning_type: full
# dataset
dataset: custom_data_name
custom_dataset_info: custom_dataset_info.json
cutoff_len: 1024
template: deepseek_r1
deepspeed: examples/deepspeed/ds_z2_config.json
# output
output_dir: saves/deepseek_r1_distill_qwen_7b_full
logging_steps: 10
save_steps: 20
overwrite_output_dir: true
# train
per_device_train_batch_size: 2
gradient_accumulation_steps: 1
learning_rate: 1.0e-5
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
max_steps: 50
seed: 1234
关键参数说明:配置设置了原始模型的路径, 微调方法为full,template设置为deepseek_r1, 数据方面引用了前面第3步定义的配置,并使用了 deepspeed 的zero2算法(项目源码中的示例),并设定了模型保存的路径为saves/deepseek_r1_distill_qwen_7b_full,完整的参数说明可参考文档
如果是LoRA低参微调,只需要把finetuning_type修改为lora即可, 与之对应的是训练保存的参数只会保存LoRA部分。
5 训练启动
训练启动时,使用如下命令即可, 传入上面定义的yaml配置文件,使用ASCEND_RT_VISIBLE_DEVICES控制NPU设备的数量和编号。
ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 openmind-cli train train_sample.yaml
训练过程中会输出日志,包含loss等,等待训练完成后,即可在配置中的output_dir获取到微调后的模型权重。